Google Earth Engine Data Pipeline
Automating Environmental Data Collection for Faster, More Reliable Analysis
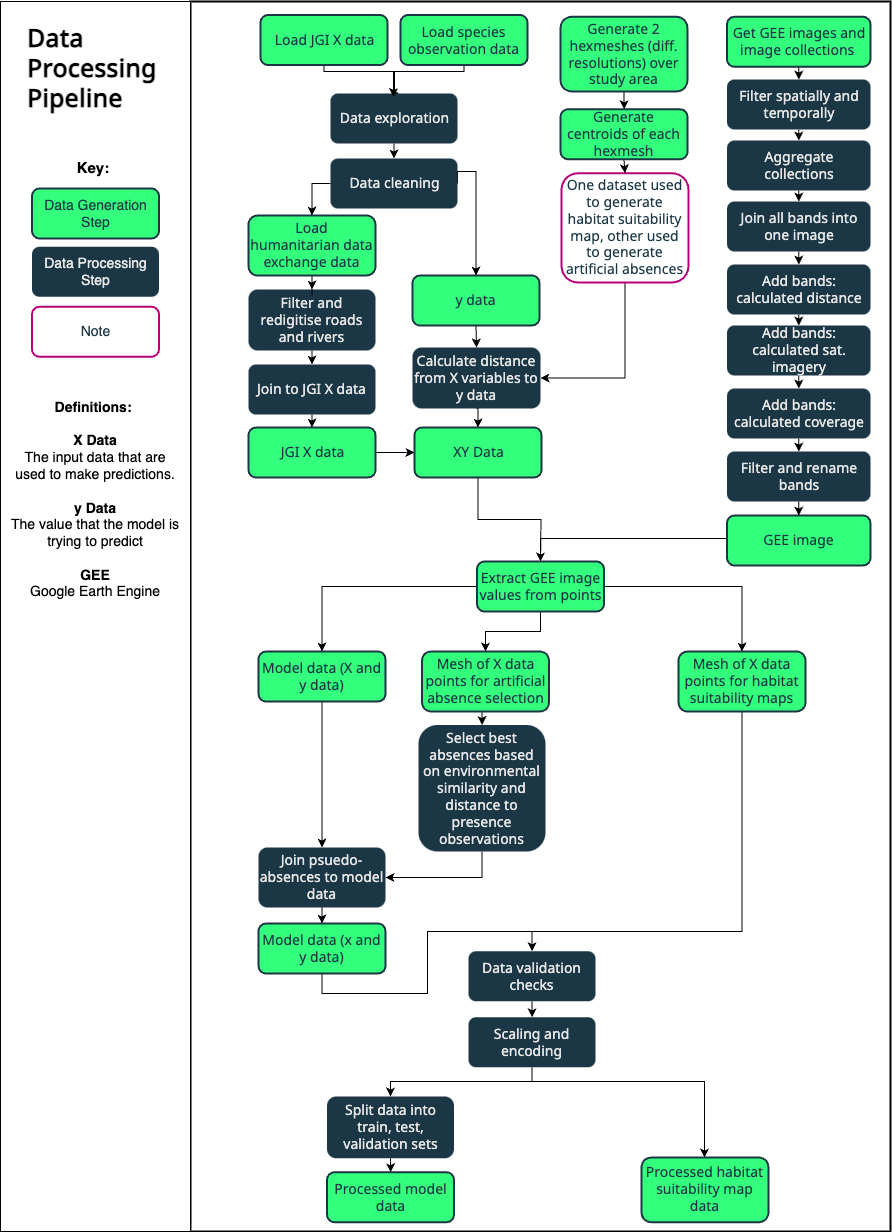
Environmental analysis typically begins with tedious data preparation: identifying relevant satellite imagery, downloading datasets, aligning projections and resolutions, clipping to study areas, and combining everything for analysis. This manual work consumes time before analysis can begin and must be repeated for every new project, often requiring GIS and Remote Sensing expertise alongside ecological knowledge.
I developed a Python module that automates global environmental data collection through the Google Earth Engine API. A user provides a polygon defining their study area, and the module handles selection of appropriate satellite imagery and environmental datasets, applies necessary processing and quality filters, combines multiple data sources, and exports results either as raster files or as gridded point data with values extracted from cell centroids.
The module integrates with the Global Biodiversity Information Facility to pull species occurrence records, and can also incorporate locally stored datasets. Additional utility functions handle common preprocessing tasks such as data cleaning, joining and validation.
This module now serves as core infrastructure for both the habitat suitability modeling platform and Wildmon’s broader data pipeline. What previously required days of specialist work now takes hours. Processes that required a team can now be performed by ecologists and subject matter experts alone, while ensuring every project uses the same rigorous data collection workflow.
Project Partners
